Опубликован: 25.11.2008 | Доступ: свободный | Студентов: 5733 / 1075 | Оценка: 4.46 / 4.18 | Длительность: 24:42:00
Тема: Базы данных
Специальности: Администратор баз данных
Теги:
Лекция 9:
Физические модели баз данных
Моделирование отношений "один-ко-многим" на файловых структурах
Отношение иерархии является типичным для баз данных, поэтому моделирование иерархических связей является типичным для физических моделей баз данных.
Для моделирования отношений 1:М (один-ко-многим) и М:М (многие-ко-многим) на файловых структурах используется принцип организации цепочек записей внутри файла и ссылки на номера записей для нескольких взаимосвязанных файлов.
Моделирование отношения 1:М с использованием однонаправленных указателей
В этом случае связываются два файла, например F1 и F2, причем предполагается, что одна запись в файле F1 может быть связана с несколькими записями в файле F2. Условно это можно представить в виде, изображенном на рис. 9.10.

При этом файл F1 в этом комплексе условно называется "Основным", а файл F2 — "зависимым" или "подчиненным". Структура основного файла может быть условно представлена в виде трех областей.
"Основной файл" F1.
| Ключ | Запись | Ссылка-указатель на первую запись в "Подчиненном" файле, с которой начинается цепочка записей файла F2, связанных с данной записью файла F1 |
|---|
В подчиненном файле также к каждой записи добавляется специальный указатель, в нем хранится номер записи, которая является следующей в цепочке записей "подчиненного" файла, связанной с одной записью "основного" файла.
Таким образом, каждая запись "подчиненного файла" делится на две области: область указателя и область, содержащую собственно запись.
Структура записи "подчиненного" файла.
В качестве примера рассмотрим связь между преподавателями и занятиями, которые эти преподаватели проводят. В файле F1 приведен список преподавателей, а в файле F2 — список занятий, которые они ведут.
| F1 | ||
|---|---|---|
| Номер записи | Ключ и остальная запись | Указатель |
| 1 | Иванов И. Н. 
|
1 |
| 2 | Петров А. А. | 3 |
| 3 | Сидоров П. А. | 2 |
| 4 | Яковлев В. В. | |
| F2 | ||
|---|---|---|
| Номер записи | Указатель на следующую запись в цепочке | Содержимое записи |
| 1 | 4 | 4306 Вычислительные сети |
| 2 | - | 4307 Контроль и диагностика |
| 3 | 6 | 4308 Вычислительные сети |
| 4 | 5 | 84305 Моделирование |
| 5 | - | 4309 Вычислительные сети |
| 6 | - | 84405 Техническая диагностика |
| 7 | - | |
В этом случае содержимое двух взаимосвязанных файлов F1 и F2 может быть расшифровано следующим образом: первая запись в файле F1 связана с цепочкой записей файла F2, которая начинается с записи номер 1, следующая запись номер 4 и последняя запись в цепочке — запись номер 5. Последняя — потому что пятая запись не имеет ссылки на следующую запись в цепочке. Аналогично можно расшифровать и остальные связи. Если мы проведем интерпретацию данных связей на уровне предметной области, то можно утверждать, что преподаватель Иванов ведет предмет " Вычислительные сети" в группе 4306, "Моделирование" в группе 84305 и "Вычислительные сети" в группе 4309.
Аналогично могут быть расшифрованы и остальные взаимосвязанные записи.
Алгоритм нахождения нужных записей "подчиненного" файла
- Шаг 1.Ищется запись в "основном" файле в соответствии с его организацией (с помощью функции хэширования, или с использованием индексов, или другим образом). Если требуемая запись найдена, то переходим к шагу 2, в противном случае выводим сообщение об отсутствии записи основного файла.
- Шаг 2.Анализируем указатель в основном файле если он пустой, то есть стоит прочерк, значит, для этой записи нет ни одной связанной с ней записи в "подчиненном файле", и выводим соответствующее сообщение, в противном случае переходим к шагу 3.
- Шаг 3.По ссылке-указателю в найденной записи основного файла переходим прямым методом доступа по номеру записи на первую запись в цепочке "Подчиненного" файла. Переходим к шагу 4.
- Шаг 4.Анализируем текущую запись на содержание если это искомая запись, то мы заканчиваем поиск, в противном случае переходим к шагу 5.
- Шаг 5. Анализируем указатель на следующую запись в цепочке если он пуст, то выводим сообщение, что искомая запись отсутствует, и прекращаем поиск, в противном случае по ссылке-указателю переходим на следующую запись в "подчиненном файле" и снова переходим к шагу 4.
Использование цепочек записей позволяет эффективно организовывать модификацию взаимосвязанных файлов.
Алгоритм удаления записи из цепочки "подчиненного" файла
- Шаг 1.Ищется удаляемая запись в соответствии с ранее рассмотренным алгоритмом. Единственным отличием при этом является обязательное сохранение в специальной переменной номера предыдущей записи в цепочке, допустим, это переменная NP.
- Шаг 2.Запоминаем в специальной переменной указатель на следующую запись в найденной записи, например, заносим его в переменную NS. Переходим к шагу 3.
- Шаг 3.Помечаем специальным символом, например символом звездочка ( * ), найденную запись, то есть в позиции указателя на следующую запись в цепочке ставим символ " * " — это означает, что данная запись отсутствует, а место в файле свободно и может быть занято любой другой записью.
- Шаг 4.Переходим к записи с номером, который хранится в NP, и заменяем в ней указатель на содержимое переменной NS.
Для того чтобы эффективно использовать дисковое пространство при включении новой записи в "подчиненный файл", ищется первое свободное место, т. е. запись, помеченная символом " * ", и на ее место заносится новая запись, после этого производится модификация соответствующих указателей. При этом необходимо различать 3 случая:
- Добавление записи на первое место в цепочке.
- Добавление записи в конец цепочки.
- Добавление записи на заданное место в цепочке.
Задание для самостоятельной работы
Разработать алгоритмы добавления записи для всех трех случаев
Однако часто бывает необходимо просматривать цепочку подчиненных записей в двух направлениях: прямом и обратном. В этом случае применяют двойные указатели.
В "основном файле" один указатель равен номеру первой записи в цепочке записей "подчиненного файла", а второй — номеру последней записи.
В "подчиненном файле" один указатель равен номеру следующей записи в цепочке, а другой — номеру предыдущей записи в цепочке. Для первой и последней записей в цепочке один из указателей пуст, то есть равен пробелу.
Для нашего примера это выглядит следующим образом:
| F1 | |||
|---|---|---|---|
| Номер записи | Ключ и остальная запись | Указатель на первую запись | Указатель на последнюю запись |
| 1 | Иванов И. Н. . |
1 | 5 |
| 2 | Петров А. А. | 3 | 6 |
| 3 | Сидоров П. А. | 2 | 2 |
| 4 | Яковлев В. В. | ||
| F2 | |||
|---|---|---|---|
| Номер записи | Указатель на предыдущую запись в цепочке | Указатель на следующую запись в цепочке | Содержимое записи |
| 1 | - | 4 | 4306 Вычислительные сети |
| 2 | - | - | 4307 Контроль и диагностика |
| 3 | - | 6 | 4308 Вычислительные сети |
| 4 | 1 | 5 | 84305 Моделирование |
| 5 | 4 | - | 4309 Вычислительные сети |
| 6 | 3 | - | 84405 Техническая диагностика |
| 7 | - | ||
Один файл ("подчиненный" или "основной") может быть связан с несколькими другими файлами, при этом для каждой связи моделируются свои указатели. Связь двух основных файлов F1 и F2 с одним связующим файлом F3 моделируется на:
Инвертированные списки
До сих пор мы рассматривали структуры данных, которые использовались для ускорения доступа по первичному ключу. Однако достаточно часто в базах данных требуется проводить операции доступа по вторичным ключам. Напомним, что вторичным ключом является набор атрибутов, которому соответствует набор искомых записей. Это означает, что существует множество записей, имеющих одинаковые значения вторичного ключа. Например, в случае нашей БД "Библиотека" вторичным ключом может служить место издания, год издания. Множество книг могут быть изданы в одном месте, и множество книг могут быть изданы в один год.
Для обеспечения ускорения доступа по вторичным ключам используются структуры, называемые инвертированными списками, которые послужили основой организации индексных файлов для доступа по вторичным ключам.
Инвертированный список в общем случае — это двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в которой упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и то же значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И наконец, на третьем уровне находится собственно основной файл.
Механизм доступа к записям по вторичному ключу при подобной организации записей весьма прост. На первом шаге мы ищем в области первого уровня заданное значение вторичного ключа, а затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа, а далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа.
На рис. 9.11 представлен пример инвертированного списка, составленного для вторичного ключа "Номер группы" в списке студентов некоторого учебного заведения. Для более наглядного представления мы ограничили размер блока пятью записями (целыми числами).
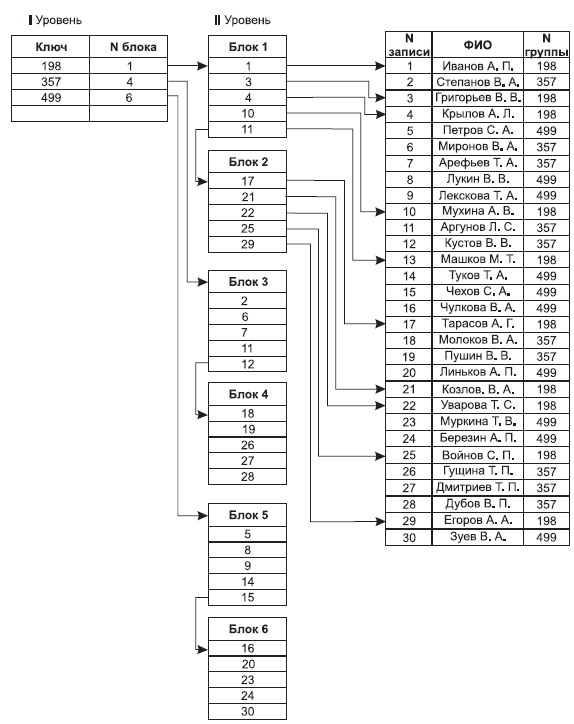
увеличить изображение
Рис. 9.11. Построение инвертированного списка по номеру группы для списка студентов
Для одного основного файла может быть создано несколько инвертированных списков по разным вторичным ключам.
Следует отметить, что организация вторичных списков действительно ускоряет поиск записей с заданным значением вторичного ключа. Но рассмотрим вопрос модификации основного файла.
При модификации основного файла происходит следующая последовательность действий:
- Изменяется запись основного файла.
- Исключается старая ссылка на предыдущее значение вторичного ключа.
- Добавляется новая ссылка на новое значение вторичного ключа.
При этом следует отметить, что два последних шага выполняются для всех вторичных ключей, по которым созданы инвертированные списки. И, разумеется, такой процесс требует гораздо больше временных затрат, чем просто изменение содержимого записи основного файла без поддержки всех инвертированных списков.
Поэтому не следует безусловно утверждать, что введение индексных файлов (в том числе и инвертированных списков) всегда ускоряет обработку информации в базе данных. Отнюдь, если база данных постоянно изменяется, дополняется, модифицируется содержимое записей, то наличие большого количества инвертированных списков или индексных файлов по вторичным ключам может резко замедлить процесс обработки информации.
Можно придерживаться следующей позиции: если база данных достаточно стабильна и ее содержимое практически не меняется, то построение вторичных индексов действительно может ускорить процесс обработки информации.